Appearance
第五章:模型架构
在本章中,我们将深入探讨大语言模型的架构设计,这是模型性能和效率的关键。我们将从Transformer模型的基本组成开始,详细介绍其核心组件和配置,以及如何通过不同的架构配置来优化模型。
4.1 Transformer模型
Transformer模型是由多层的多头自注意力(Multi-head Self-attention)模块堆叠而成的神经网络模型,它在自然语言处理领域取得了革命性的进展。 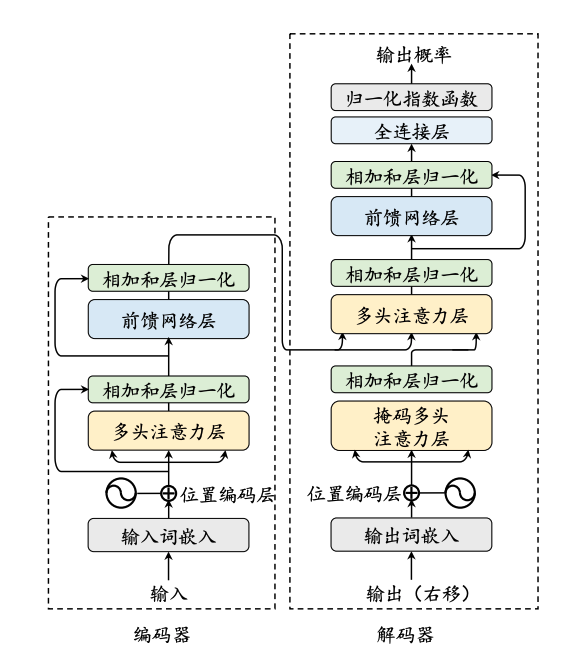
4.1.1 输入编码
输入编码是Transformer模型的第一步,它将词元序列转化为词向量序列,并结合位置编码以保留序列的顺序信息。
4.1.2 多头自注意力机制
多头自注意力机制是Transformer的核心,它允许模型同时在不同的表示子空间上捕捉信息,并增强了模型对序列中长距离依赖的建模能力。
4.1.3 前馈网络层
前馈网络层对每个位置的隐藏状态进行非线性变换,进一步提取特征,并通过激活函数引入非线性映射。
4.1.4 编码器
编码器由多个相同的层堆叠而成,每层包含多头自注意力模块和前馈网络模块,通过层归一化和残差连接来加强模型的训练稳定度。
4.1.5 解码器
解码器基于编码器的输出执行序列生成任务,引入掩码自注意力模块以保证生成目标序列时不依赖于未来的信息。
4.2 详细配置
在这一节中,我们将探讨Transformer模型的四个核心组件的配置,包括归一化方法、位置编码、激活函数和注意力机制。
4.2.1 归一化方法
归一化是提升模型训练稳定性的关键技术,我们将讨论LayerNorm、RMSNorm和DeepNorm等不同的归一化方法。
4.2.2 归一化模块位置
归一化模块的位置对模型性能有显著影响,我们将探讨层前归一化(Pre-Norm)、层后归一化(Post-Norm)和夹心归一化(Sandwich-Norm)。
4.2.3 激活函数
激活函数的选择对模型的表达能力至关重要,我们将讨论ReLU、GELU、Swish等激活函数及其在大语言模型中的应用。 
4.2.4 位置编码
位置编码是Transformer模型中处理序列顺序信息的关键,我们将讨论绝对位置编码、相对位置编码和旋转位置编码(RoPE)。
4.2.5 注意力机制
注意力机制是Transformer架构中的核心技术,我们将讨论完整自注意力、稀疏注意力、多查询/分组查询注意力和硬件优化的注意力机制。
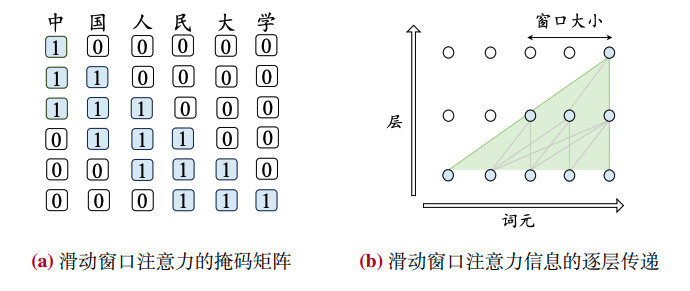

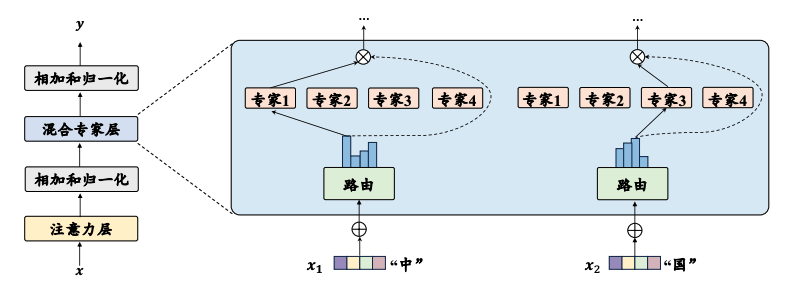
4.3 主流架构
在这一节中,我们将介绍三种主流的大语言模型架构:编码器-解码器架构、因果解码器架构和前缀解码器架构。 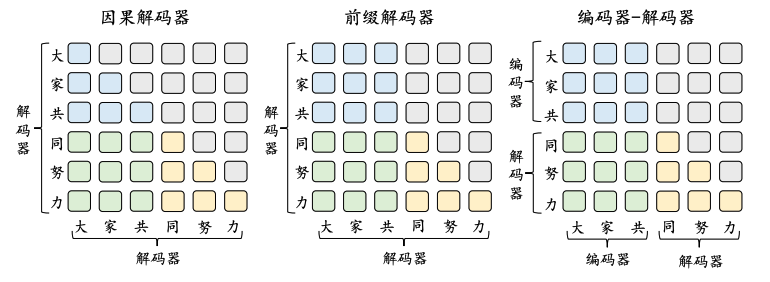
4.3.1 编码器-解码器架构
编码器-解码器架构广泛应用于机器翻译等任务,由编码器和解码器两个部分组成,分别负责处理输入和生成输出。
4.3.2 因果解码器架构
因果解码器架构,也称为单向解码器架构,主要用于生成任务,如文本摘要和对话系统。
4.3.3 前缀解码器架构
前缀解码器架构结合了编码器和解码器的特点,适用于需要同时处理输入和输出的任务。
4.4 长上下文模型
长上下文模型能够处理超出常规上下文窗口大小的长序列数据,这对于长文档分析和多轮对话等应用尤为重要。
4.4.1 扩展位置编码
为了处理长序列,需要对位置编码进行扩展,以适应更长的文本数据。
4.4.2 调整上下文窗口
除了扩展位置编码,还可以通过调整上下文窗口来增强模型对长文本的建模能力。 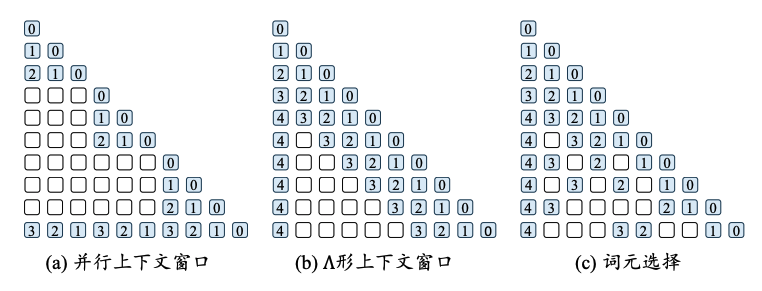
4.4.3 长文本数据
长文本数据的准备和使用对于训练有效的长上下文模型至关重要。
4.5 新型模型架构
随着研究的深入,出现了一些新型的模型架构,它们旨在提高模型的效率和性能。
4.4.1 参数化状态空间模型
参数化状态空间模型是一种新型的模型架构,它通过引入额外的状态变量来提高模型的计算效率。
4.4.2 状态空间模型变种
包括Mamba、RWKV、RetNet和Hyena等模型,它们在保持计算效率的同时,提高了模型的语言建模能力。
本章内容为读者提供了大语言模型架构设计的全面概览,包括核心组件的配置和新型架构的介绍,旨在帮助读者理解不同架构选择对模型性能的影响。