Appearance
第2章:基础介绍
本章将详细介绍大语言模型的构建过程,包括预训练和微调的基本概念、扩展法则、涌现能力以及GPT系列模型的技术演变。这些内容为理解大语言模型的工作原理和发展历程提供了基础。
2.1 大语言模型的构建过程
大语言模型的构建过程可以分为两个主要阶段:大规模预训练和指令微调与人类对齐。
2.1.1 大规模预训练
预训练是指使用大量无标注数据对模型进行训练,以学习通用的语言表示。这一阶段的目标是让模型掌握丰富的语言知识和世界知识,为后续的微调和任务执行打下基础。
- 数据准备:收集和清洗大规模的文本数据,包括网页、书籍、维基百科等,以确保数据的多样性和质量。
- 模型训练:使用预训练任务(如语言建模)训练模型,使其能够预测文本序列中的下一个词元。
- 资源需求:预训练阶段需要大量的计算资源,包括高性能的GPU和大量的存储空间。
2.1.2 指令微调与人类对齐
预训练后的模型虽然具备了一定的语言能力,但还需要通过微调来适应特定的任务和应用场景。
- 指令微调:使用标注好的任务数据对模型进行微调,使其能够理解和执行具体的指令。
- 人类对齐:通过人类反馈来调整模型的行为,使其输出更加符合人类的价值观和期望。
2.2 扩展法则
扩展法则描述了模型性能随模型规模、数据规模和计算资源增加而提升的规律。这一法则对于理解和设计大语言模型至关重要。
- KM扩展法则:由OpenAI提出,描述了模型性能与模型规模、数据规模和计算资源之间的关系。
- Chinchilla扩展法则:由DeepMind提出,强调了数据规模在模型扩展中的重要性。
2.3 涌现能力
涌现能力指的是大语言模型在达到一定规模后展现出的、小规模模型不具备的能力。这些能力通常与模型的复杂任务处理能力相关。
- 上下文学习:大模型能够在给定上下文的情况下,通过少量示例学习新任务。
- 指令遵循:大模型能够理解和执行自然语言形式的任务指令。
- 逐步推理:大模型能够在复杂任务中展现出逐步推理的能力。
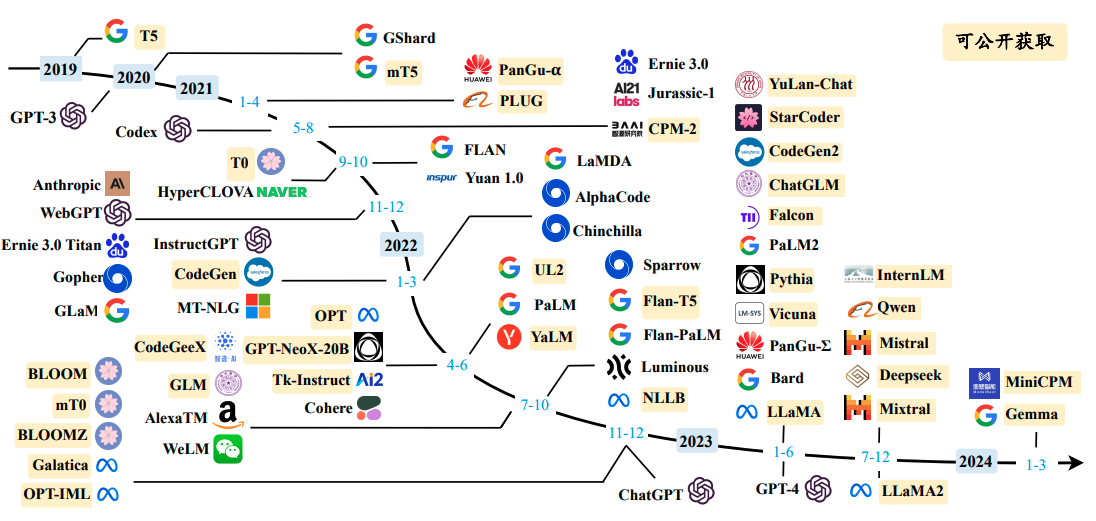
2.4 GPT系列模型的技术演变
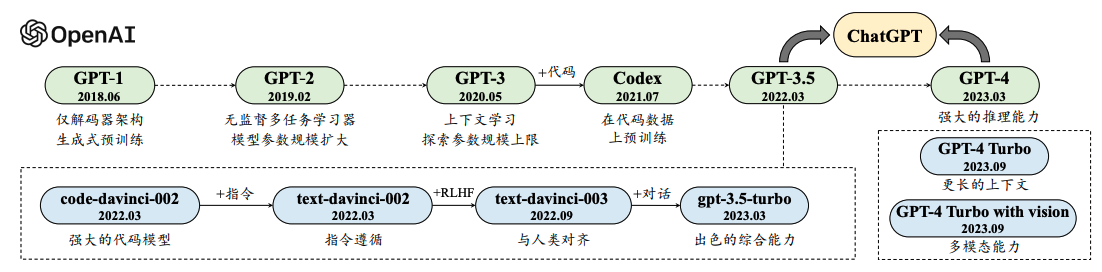
GPT系列模型是大语言模型的代表,其技术演变反映了大语言模型技术的进步。
- GPT-1:引入了基于Transformer的预训练方法,奠定了大语言模型的基础。
- GPT-2:通过扩大模型规模,探索了模型性能的扩展性。
- GPT-3:进一步扩大模型规模,展示了大模型在多种任务上的强大能力。
- GPT-4:在GPT-3的基础上,进一步提升了模型的性能和多模态能力。
本章内容为读者提供了大语言模型构建过程的全面概览,以及对其关键技术和能力的理解。后续章节将深入探讨预训练、微调、模型架构和应用等具体内容。