Appearance
第三章:数据准备
在大语言模型的预训练阶段,高质量的数据准备是至关重要的。本章将详细介绍如何收集、清洗、预处理和调度预训练数据,以确保模型能够有效地学习和泛化。
3.1 数据来源
为了构建功能强大的大语言模型,需要从多元化的数据源中收集海量数据进行训练。这些数据源包括网页、书籍、维基百科、代码和对话数据等。 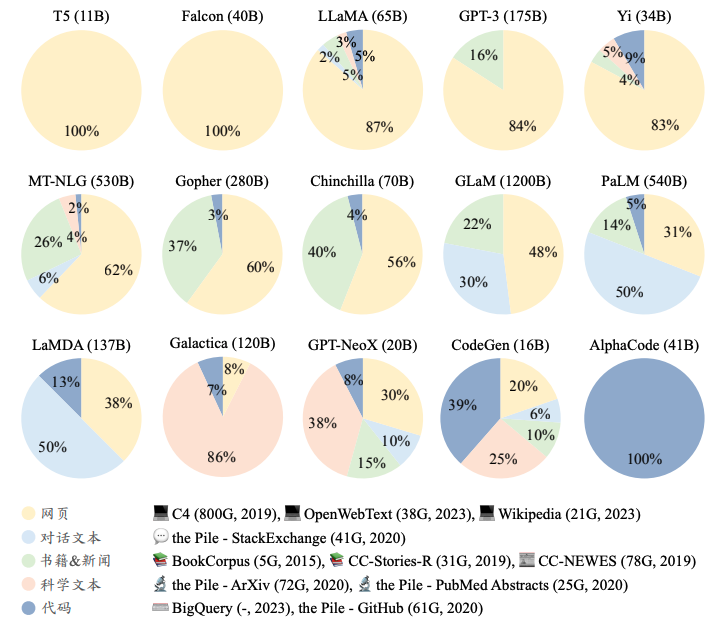
3.1.1 通用文本数据
通用文本数据是大语言模型预训练的基础,它们通常包括网页、书籍和对话文本等。这些数据覆盖了多个主题类别的文本内容,有助于模型积累丰富的语言知识。
3.1.2 专用文本数据
专用文本数据,如多语言数据、科学数据和代码数据,有助于提升大语言模型在特定专业任务上的表现。
3.2 数据预处理
收集到的原始数据往往包含噪声、重复内容和不相关信息,因此需要进行预处理以提升数据质量。 
3.2.1 质量过滤
质量过滤旨在去除低质量的数据,如机器生成的广告网页或含有错误和不自然句子的内容。
3.2.2 敏感内容过滤
敏感内容过滤用于去除有毒内容或隐私信息,以确保数据的纯净度和安全性。
3.2.3 数据去重
数据去重是删除在训练集中出现的重复或相关文本,防止模型过度学习这些模式,影响性能。
3.3 词元化(分词)
词元化是将原始文本分割成模型可识别和建模的词元序列的过程。常见的词元化方法包括BPE分词、WordPiece分词和Unigram分词。
3.3.1 BPE分词
BPE分词是一种基于频率的词元化方法,通过迭代合并连续的词元来构建词汇表。
3.3.2 WordPiece分词
WordPiece分词与BPE类似,但它使用语言模型对所有可能的词元对进行评分,然后选择使得数据似然性增加最多的词元对进行合并。
3.3.3 Unigram分词
Unigram分词从一个大的字符串或词元初始集合开始,迭代地删除其中的词元,直到达到预期的词表大小。
3.4 数据调度
数据调度涉及安排预训练数据的顺序和混合比例,以优化模型的学习过程。 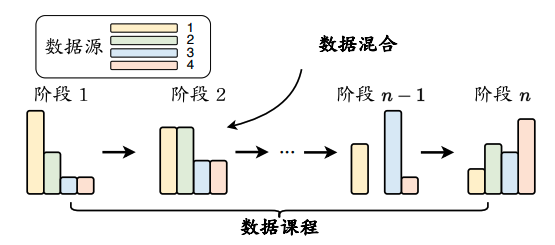
3.3.1 数据混合
数据混合是指根据特定比例从不同数据源中采样数据,以创建用于训练的数据集合。
3.3.2 数据课程
数据课程是指按照特定的顺序安排预训练数据进行模型的训练,例如从简单/通用的数据开始,逐渐引入更具挑战性/专业化的数据。
3.3.3 预训练数据准备概述——以YuLan模型为例
本节将概述YuLan模型预训练阶段的数据准备流程,包括数据收集、清洗、词元化和调度。
本章内容为读者提供了大语言模型预训练阶段数据准备的详细指导,这些步骤对于确保模型能够有效地学习和泛化至关重要。